Анализ алгоритмов
Несмотря на то, что производительность компьютеров постоянно возрастает, она не может быть бесконечно большой. Поэтому, время вычисления — это ограниченный ресурс, так же, как и объём необходимой памяти. В случае, когда речь идёт именно о времени вычисления, мы будем употреблять термин «временная сложность». Если речь будет идти о памяти в каком-либо виде, то будет говорить «пространственная сложность».
Простой способ оценить работу алгоритма — это посчитать количество инструкций, необходимых для его завершения. Это могут быть ассемблерные команды или инструкции трёхадресного кода. Поскольку любой алгоритм должен быть разбит на шаги, то всегда будет возможность эти шаги сосчитать.
При добавлении одного цикла приходится умножать количество инструкций, заключенных в теле цикла, на количество итераций. В этом случае, говорят, что алгоритм линейно зависит от числа итераций n. Часто этот параметр задаётся неявно, как размер входного массива данных. В таком случае говорят о линейной зависимости от размера данных.
fun findMax(list: IntList): Int {
var max = list.first()
for (i in 0 until list.size) {
if (list[i] > max) {
max = list[i]
}
}
return max
}
В случае вложенных циклов количество итераций перемножаются. Если количество итераций в циклах равное, то можно говорить про квадратичную зависимость. Такие оценки работы алгоритма часто встречаются при работе с матрицами, изображениями и в других структурах, в которых необходимо обрабатывать строки и столбцы.
fun isIdentityMatrix(list: List): Boolean { for (i in 0 until list.size) { val row = list[i] if (row.length != list.size) { return false; } for (j in 0 until row.size) { if (j == i && row[i] != 1) return false; if (j != i && row[i] != 0) return false; } } return true }
Для понимания того, как зависимость от размера данных влияет на общее время работы алгоритма, рассмотрим следующий пример. Допустим, существуют 2 разных алгоритма, решающих одну и ту же задачу. Первый алгоритм решает задачу за  команд, второй алгоритм за
команд, второй алгоритм за  . Попробуем сравнить время их выполнения на двух разных компьютерах А и Б. Предположим также, что компьютер А в тысячу раз быстрее компьютера Б и выполняет
. Попробуем сравнить время их выполнения на двух разных компьютерах А и Б. Предположим также, что компьютер А в тысячу раз быстрее компьютера Б и выполняет  команд в секунду. Запустим первый алгоритм на компьютере А, а второй на компьютере Б для n=
команд в секунду. Запустим первый алгоритм на компьютере А, а второй на компьютере Б для n= .
.

Более быстрый компьютер с менее эффективным алгоритмом при наших вводных отработает примерно за 5 с половиной часов. Медленный компьютер с более эффективным алгоритмом справится с задачей менее чем за 20 минут.
Как мы можем видеть, зависимость числа инструкций от входных параметров влияет намного сильнее, чем увеличение производительности вычислительной машины.
Рост целевой функции  имеет различные названия:
имеет различные названия:
- Константное (время работы не зависит от n)
- Логарифмическое (
 : напр., двоичный поиск)
: напр., двоичный поиск)
- Линейное (
 : напр., поиск максимального значения)
: напр., поиск максимального значения)
- Квазилинейное (
 : напр., большинство эффективных сортировок)
: напр., большинство эффективных сортировок)
- Квадратичное (
 : напр., обход значений матрицы)
: напр., обход значений матрицы)
- Полиномиальное (
 для c>1)
для c>1)
- Экспоненциальное (
 для c>1)
для c>1)
- Факториальное (
 : напр., задача коммивояжёра)
: напр., задача коммивояжёра)
При определённом наборе данных алгоритм может иметь разную временную сложность. Так, к примеру, простая реализация сортировки пузырьком работает за квадратичное время, то есть за для всех входных данных. Но при простой модификации, которая проверяет, что входной массив данных уже отсортирован, достаточно одного прохода по всем элементам. Другими словами, если запустить сортировку для отсортированного массива, что будет являться лучшим случаем, то алгоритм выполнится за линейное время. В таком случае говорят, что алгоритм работает за линейное время в лучшем и за квадратичное время в худшем случае.
Иногда посчитать работу алгоритма в худшем или лучшем случае не представляется возможным. Тогда для оценки скорости роста функции применяют подсчёт в среднем.
Для выполнения подсчёта в среднем используется вероятностный анализ алгоритма. Суть которого заключается в определении всех вероятностей получить на вход какие-то входные значения заданного размера n, после чего рассчитывается математическое ожидание соответствующей случайной величины, как сумма произведения времени работы определённого набора величин на его вероятность.
 , на вход которого подаётся вход x, как
, на вход которого подаётся вход x, как  . Для определения среднего случая рассмотрим конечное множество
. Для определения среднего случая рассмотрим конечное множество  входов размеров n. Предположим, что каждому входу
входов размеров n. Предположим, что каждому входу  приписана вероятность
приписана вероятность  . На заданном таким образом вероятностном пространстве сложностью в среднем называют математическое ожидание соответствующей случайной величины:
. На заданном таким образом вероятностном пространстве сложностью в среднем называют математическое ожидание соответствующей случайной величины:

Например, для алгоритма двоичного (бинарного) поиска среднее время работы можно определить, следуя следующим соображениям: вероятность найти элемент на первом шаге равна  , где n — длина отсортированной последовательности. Если на первом шаге элемент не найден, то найти его в подпоследовательности размером n/2 равна
, где n — длина отсортированной последовательности. Если на первом шаге элемент не найден, то найти его в подпоследовательности размером n/2 равна  , в подподследовательности размером n/4 соответственно
, в подподследовательности размером n/4 соответственно  . Тогда вероятность обнаружить элемент на i-м шаге будет
. Тогда вероятность обнаружить элемент на i-м шаге будет  . Максимум таких шагов может быть
. Максимум таких шагов может быть  , тогда среднее количество шагов которое нужно сделать для того, чтобы найти элемент будет:
, тогда среднее количество шагов которое нужно сделать для того, чтобы найти элемент будет:
![\[ T(n) = \sum_{x=1}^{\log_2 n} i\frac{2^{i - 1}}{n} = \frac{1}{n}\sum_{x=1}^{\log_2 n} i 2^{i - 1} \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-7a51669ef8067c9bc8c17cc9ecc8e07d_l3.svg "Rendered by QuickLaTeX.com")
![\[ \sum_{i=1}^{\log_2 n} i 2^{i - 1} = n \log_2 n - n + 1 \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-e433aa92ed095fdd973ffea3e82264bf_l3.svg "Rendered by QuickLaTeX.com")
![\[ T(n) = \frac{n \log_2 n - n + 1}{n} \approx \log_2 n \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-62368d91d283b8d64fcbec18a5f7b75c_l3.svg "Rendered by QuickLaTeX.com")
Асимптотический анализ
Расчёт значений с точными коэффициентами является сложным, а иногда и невозможным. В этом случае удобно абстрагироваться от некоторых деталей. Допустим, что для некоторого алгоритма среднее время работы можно выразить полиномом второй степени. Несомненно было бы удобно упростить его, чтобы:
- не учитывать информацию, которая несильно влияет на итоговую формулу,
- легко было оценивать время работы,
- легко было сравнивать алгоритмы между собой.
Для этого можно использовать вместо точной оценки временной сложности её асимптотическую оценку, которая может быть выражена одной из 3 греческих букв:
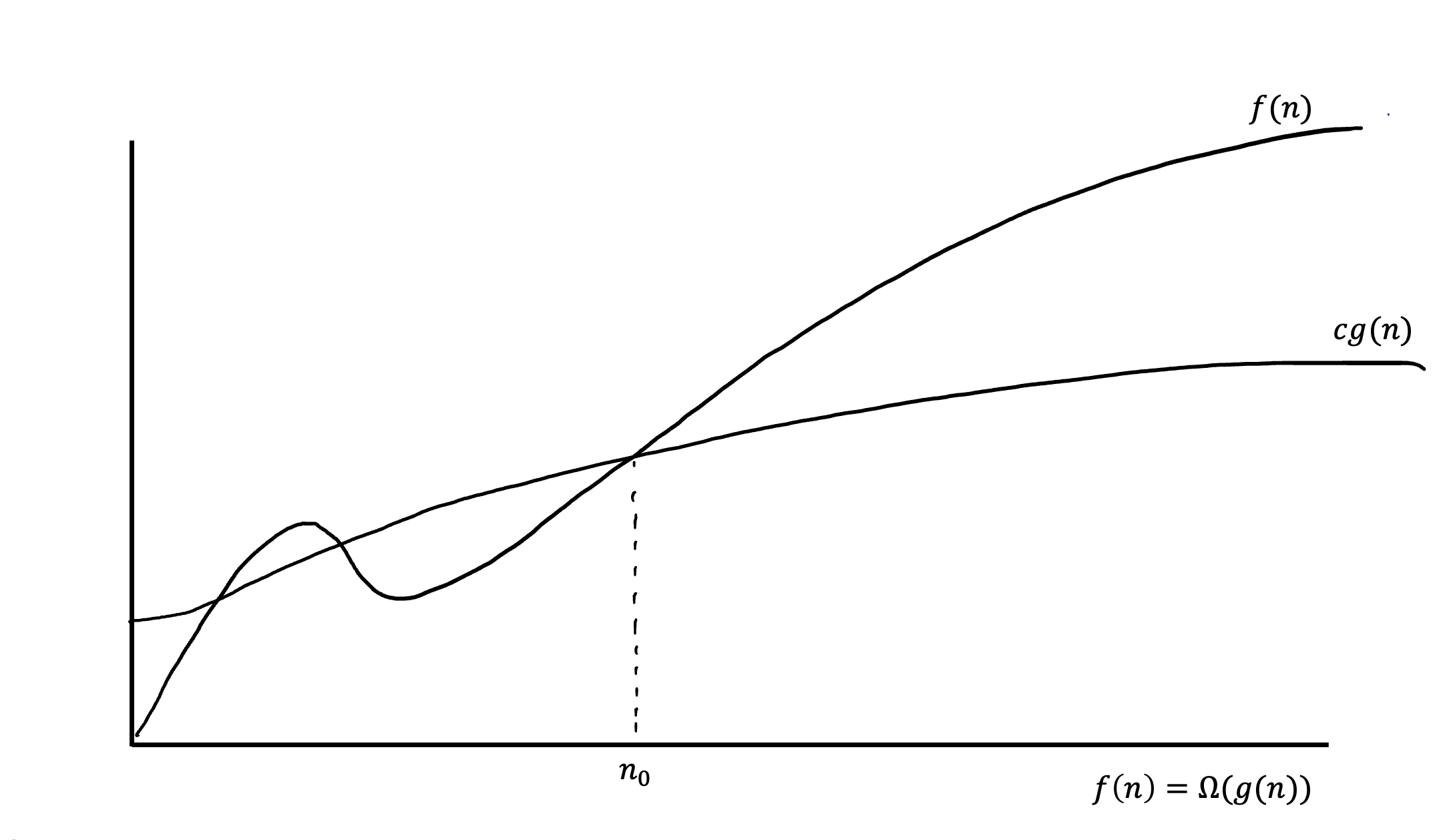
Θ(g(n)) — асимптотически точная граница. Тогда для такой функции g(n) это обозначение будет означать множество таких функций, что:
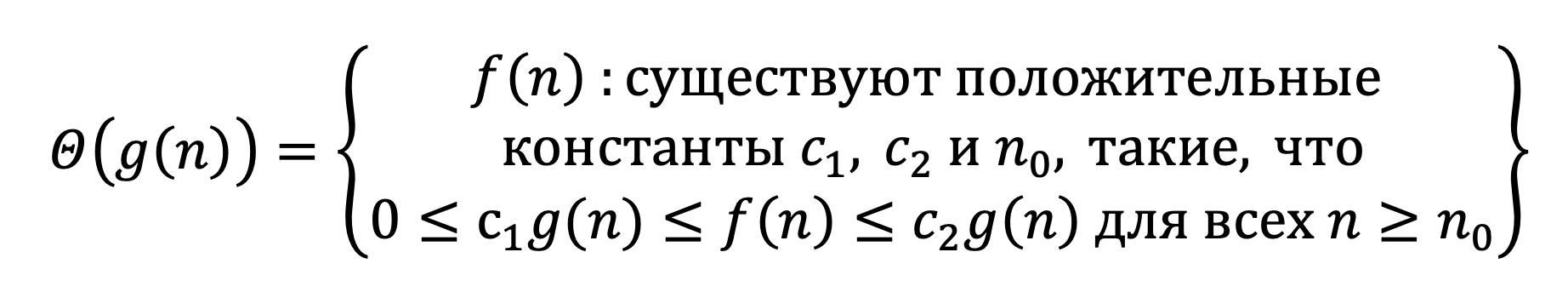
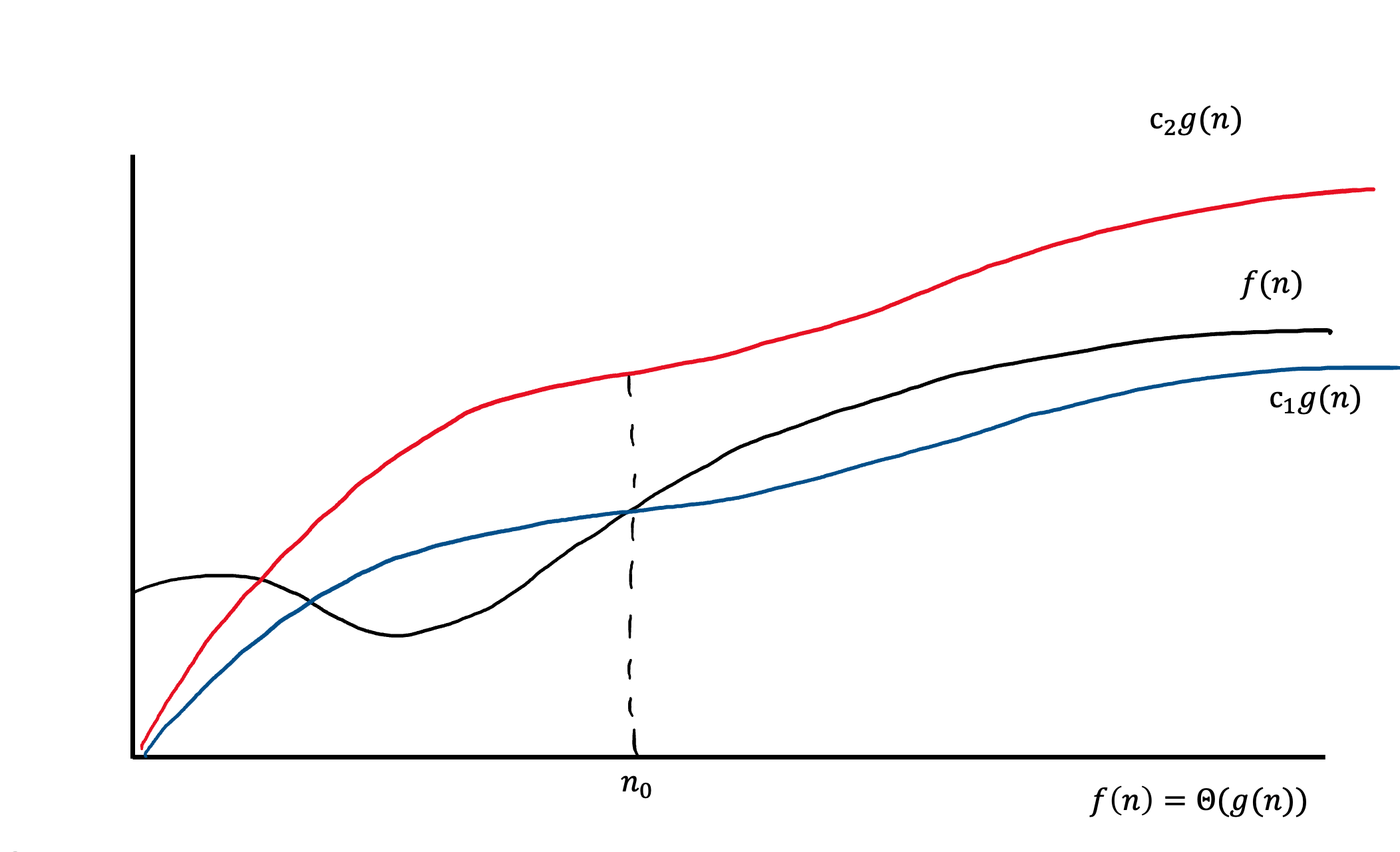
Другими словами, эту оценку можно применять ко всем функциям, которые оказываются стиснутыми между красным и синем графиками. На изображении видно, что эти графики являются одной и той же функцией, взятой с разным коэффициентом. Также, эти функции могут вести себя иначе до некоторого значения  .
.
Ο(g(n)) — асимптотически верхняя граница, для которой все функции будут находиться ниже. Более формально:
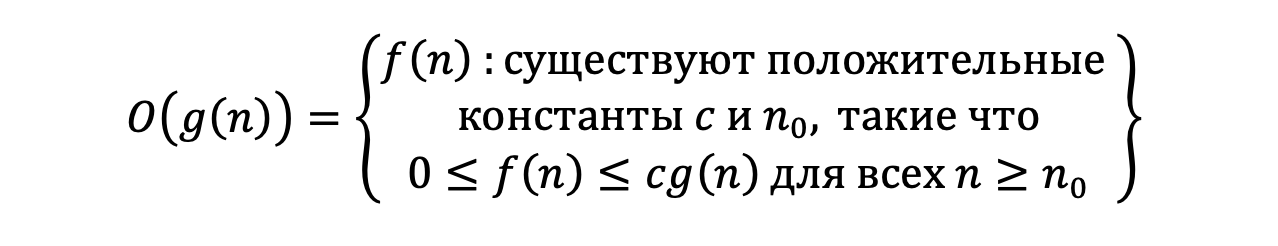
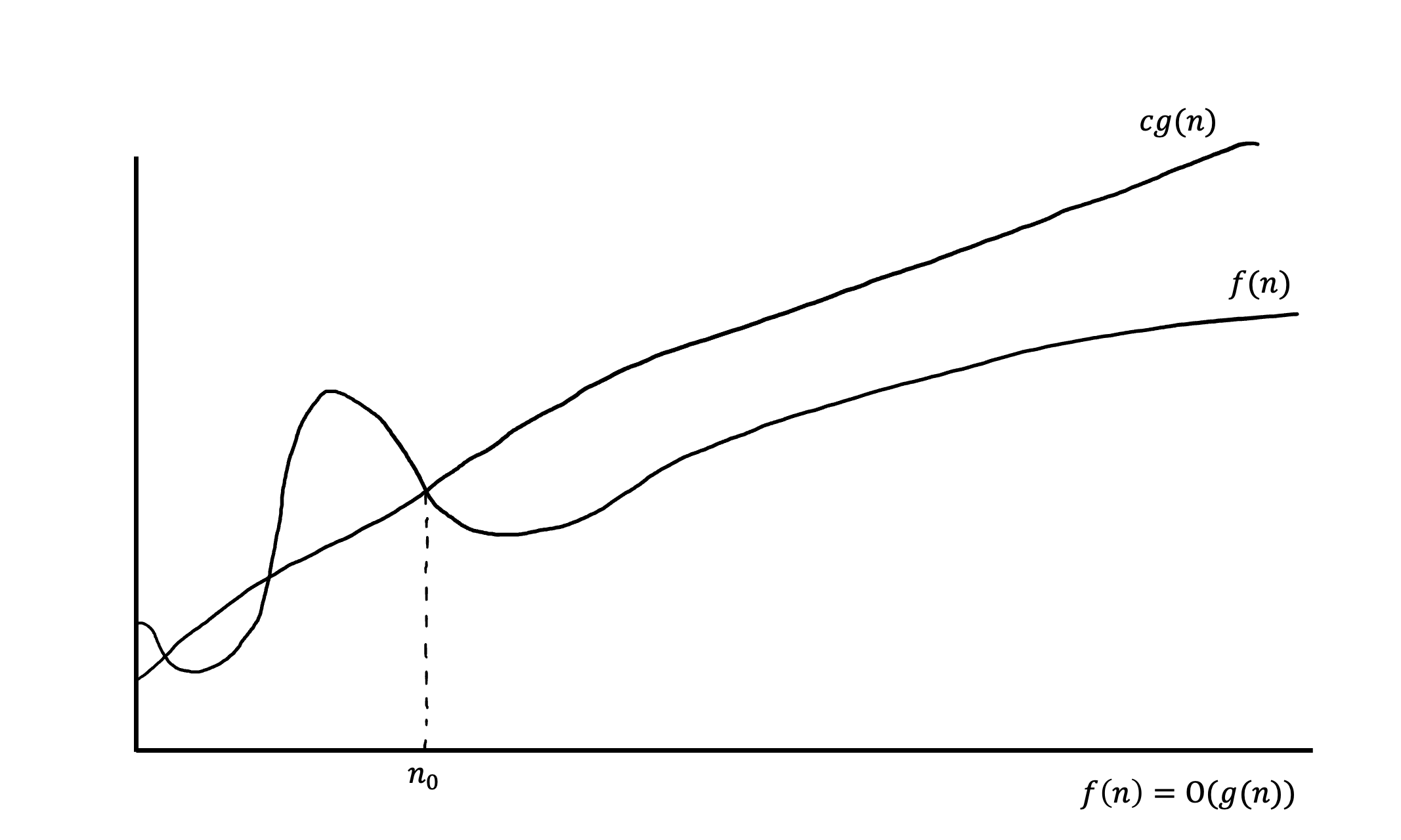
Ω(g(n)) — асимптотически нижняя граница, для которой все функции будут находиться выше. Или опять же более формально:
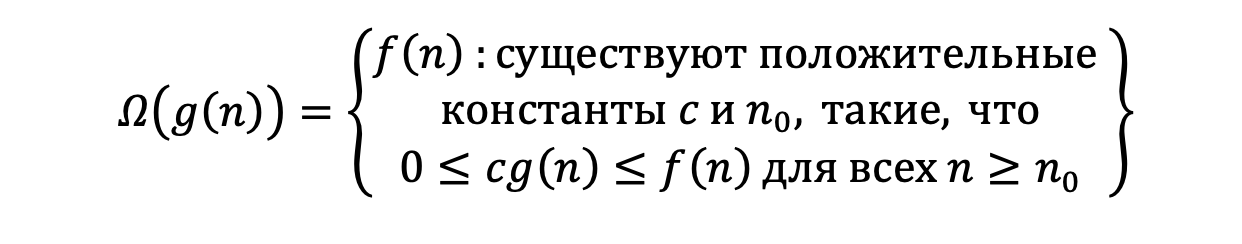
Свойства асимптотических функций
Транзитивность:
- Из f(n) = Θ(g(n)) и g(n) = Θ(h(n)) следует f(n) = Θ(h(n))
- Из f(n) = Ο(g(n)) и g(n) = Ο(h(n)) следует f(n) = Ο(h(n))
- Из f(n) = Ω(g(n)) и g(n) = Ω(h(n)) следует f(n) = Ω(h(n))
Рефлексивность:
- f(n) = Θ(f(n))
- f(n) = Ο(f(n))
- f(n) = Ω(f(n))
Симметрия:
- f(n) = Θ(g(n)) тогда и только тогда, когда g(n) = Θ(f(n))
Перестановочная симметрия:
- f(n) = Ο(g(n)) тогда и только тогда, когда g(n) = Ω(f(n))
Оценка работы рекурсивных алгоритмов
Рекурсивными являют такие алгоритмы, которые в ходе работы могут вызывать сами себя с другими аргументами. Обычно, размер данных для обработки при этом уменьшается. Это свойство лежит в основе концепции «Разделяй и властвуй». Для них в алгоритме можно выделить 3 основных шага:
- Разделение задачи на несколько подзадач, которые представляют собой меньшие экземпляры той же задачи.
- Обработка подзадач путём их рекурсивного решения. Если размеры подзадач малы, то такие подзадачи решаются непосредственно.
- Комбинирование подзадач в решение исходной задачи.
Возьмём для примера работу двоичного поиска. Здесь время работы будет константным, если n = 1, либо суммой времени работы подзадачи и собственными задачами. В задаче двоичного поиска к собственным задачам относятся, например, получение элемента по нужному индексу, сравнение его с искомым элементом, определение, какую из двух половин выбрать для дальнейшего поиска. Подзадача же на каждом шаге уменьшается вдвое. Всё это можно выразить в виде рекуррентного соотношения.
![\[ T(n) = \begin{cases} \Theta(1), \text{when } n = 1 \\ T(\frac{n}{2}), \text{when } n > 1 \end{cases} \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-cda7dd95dc4816eab00c1b07b6a914cc_l3.svg "Rendered by QuickLaTeX.com")
Существуют разные методы для определения общего времени работы рекурсивных алгоритмов, например:
- Метод подстановки
- Дерево рекурсии
- Мастер-теорема
Метод подстановки
Суть метода подстановки заключается в попытке «догадаться», как будет выглядеть оценка функции, после чего методом индукции проверить её на правильность.
Покажем это для двоичного поиска, для которого известно, что  .
.
Сначала докажем, что в индукции срабатывает переход от предыдущего значения к следующему. Допустим, что  . Тогда необходимо показать, что
. Тогда необходимо показать, что  для правильно подобранного значения
для правильно подобранного значения  .
.
Предположим, что это ограничение уже верно для всех значений  . Например, для
. Например, для  , тогда
, тогда  . Подставляя в исходное рекуррентное соотношение получаем:
. Подставляя в исходное рекуррентное соотношение получаем:
![\[ T(n) = T(\frac{n}{2}) + \Theta(1) \le c \log_2 \frac{n}{2} + d = c \log_2 n - c + d \le c \log_2 n \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-9b0b24c8e278aeb7da6ed70590f2ff66_l3.svg "Rendered by QuickLaTeX.com")
Последнее неравенство выполняется при c ≥ 1 и d ≤ c. А значит шаг индукции доказан.
Теперь необходимо найти базис индукции. Поскольку  , а
, а  для любого c, выражение
для любого c, выражение  не является истиной и не может быть базой, если d > 0. Воспользуемся тем, что для асимптотических оценок достаточно найти при котором соотношение становится верным:
не является истиной и не может быть базой, если d > 0. Воспользуемся тем, что для асимптотических оценок достаточно найти при котором соотношение становится верным:
![\[ T(1) = d, c \log_2 1 = 0 \Rightarrow d \le 0 \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-2e9ea8e54d6fa9bbcba92d2288de9653_l3.svg "Rendered by QuickLaTeX.com")
![\[ T(2) = 2d, c \log_2 2 = c \Rightarrow 2d \le c \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-d36964b6a276854fceee7b986850f228_l3.svg "Rendered by QuickLaTeX.com")
![\[ T(4) = 3d, c \log_2 4 = 2c \Rightarrow 3d \le 2c \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-f7f1309b3708ea0b2c34dbfca03fafb9_l3.svg "Rendered by QuickLaTeX.com")
Возьмем базис при  , тогда при
, тогда при  индукция будет доказана.
индукция будет доказана.
Метод дерева рекурсий
В методе дерева рекурсии все вызовы изображаются в виде дерева, для каждого вызова определяется его стоимость, после чего достаточно будет посчитать сумму всех стоимостей.
Рассмотрим дерево рекурсии для двоичного поиска. В нём каждый узел, начиная с корневого, будет порождать только одну ветвь работы алгоритма: алгоритм выбирает либо левую, либо правую половину. Всего таких разбиений будет  , т. к. при каждом разбиении размер входных данных уменьшается вдвое. Показать это можно, определив, что на k-ом вызове функции размер входных данных уменьшится ровно в
, т. к. при каждом разбиении размер входных данных уменьшается вдвое. Показать это можно, определив, что на k-ом вызове функции размер входных данных уменьшится ровно в  . Если зафиксировать, что на этом шаге размер данных равен 1, то решив уравнение получается, что
. Если зафиксировать, что на этом шаге размер данных равен 1, то решив уравнение получается, что  , где k — последний шаг рекурсии и высота дерева.
, где k — последний шаг рекурсии и высота дерева.
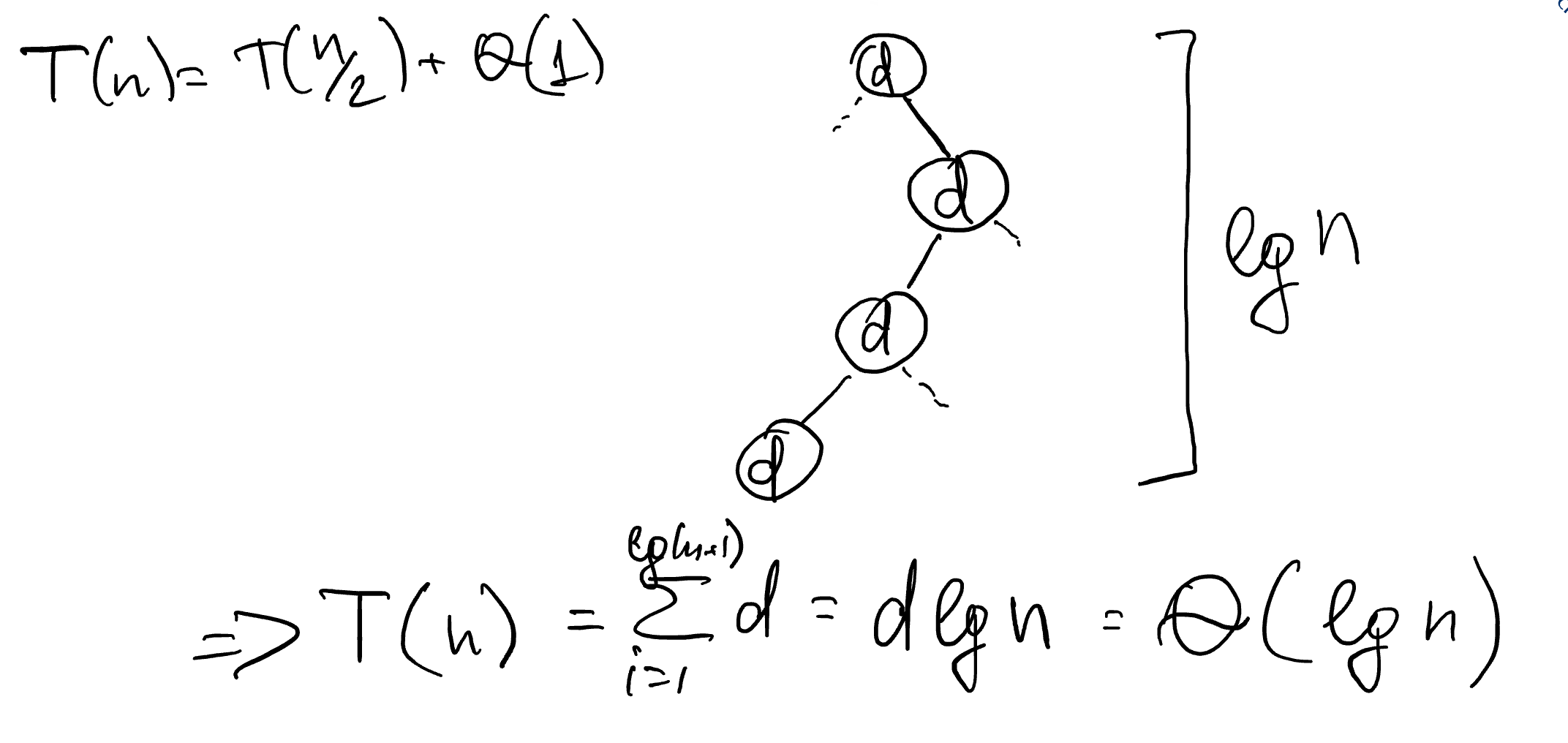
Просуммировав стоимость каждой операции d k раз определим, что:
![\[ T(n) = d \log_2 n = \Theta(\log_2 n) \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-6dc5be0fd3bebc275a28e7f70192a4a5_l3.svg "Rendered by QuickLaTeX.com")
Рассмотрим другой пример, где стоимость каждого узла линейно зависит от размера данных, а каждая задача разбивается на 4 подзадачи, в каждую из которых уходит половина данных. Тогда на i-м уровне получаем стоимость обработки подзадачи как  .
.
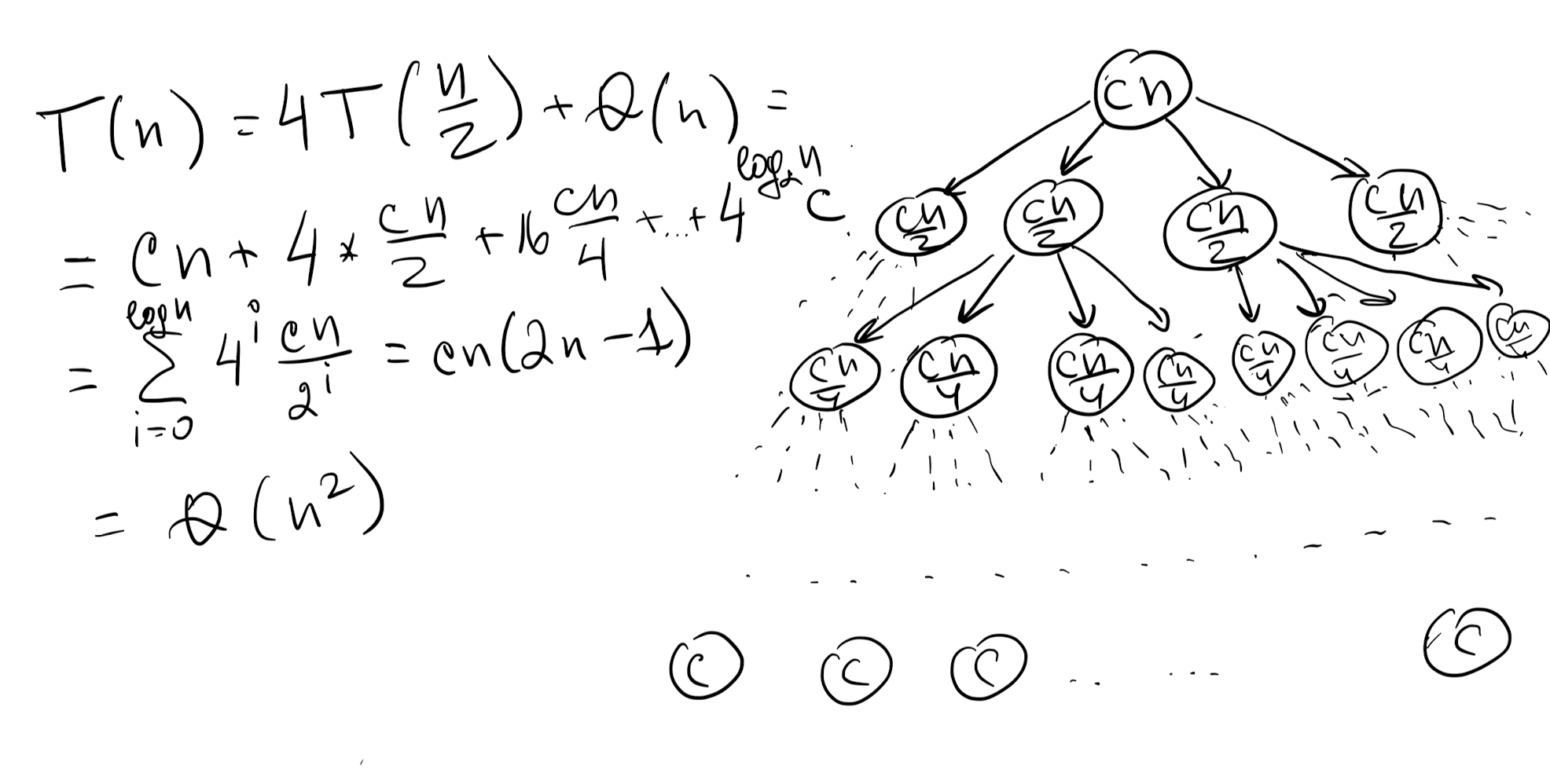
Высота дерева напрямую зависит от того, как быстро уменьшается количество данных. В данном случае на каждом уровне количество данных в 2 раза меньше, а следовательно высота дерева будет ограничена . Тогда просуммировав все элементы получим, что:
![\[ T(n) = cn(2n - 1) = \Theta(n^2) \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-b31a596d906437000efdbb542e083250_l3.svg "Rendered by QuickLaTeX.com")
Мы рассмотрели простые случаи, но в реальности деревья могут делиться не на равные части, например, рекуррентное соотношение может выглядеть так:
![\[ T(n) = 3T(\frac{n}{5}) + 2T(\frac{n}{4}) + T(\frac{n}{3}) \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-20122aaf298ee61bbf3fd6e2a60ec1e4_l3.svg "Rendered by QuickLaTeX.com")
Мастер теорема
Самым простым методом определения времени работы считается использование мастер-теоремы. Суть которого в том, что рекуррентное соотношение можно представить в общем виде как:
![\[ T(n)=aT(\frac{n}{b})+f(n) \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-4d79302a5ec6bd471b4892b290c999e7_l3.svg "Rendered by QuickLaTeX.com")
где a ≥ 1, b > 1, а f(n) — заданная функция. Здесь a означает количество подзадач, на которое делится исходная подзадача, а b — во сколько раз уменьшается количество данных при вызове рекурсивной функции. f(n) — это работа по обработке 1 вызова метода рекурсии. Далее ответ зависит от одного из трёх случаев, с помощью которого асимптотические оценки определяются достаточно просто:
- Если
 для некоторого ϵ > 0, то
для некоторого ϵ > 0, то 
- Если
 , то
, то 
- Если
 для некоторого ϵ > 0 и если
для некоторого ϵ > 0 и если  для некоторой c < 1, то
для некоторой c < 1, то 
Рассмотрим её применения для двоичного поиска:
![\[ T(n) = T(\frac{n}{2}) + d \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-6860f987c69a5473b89b0e07698289b5_l3.svg "Rendered by QuickLaTeX.com")
Поскольку  , то срабатывает второе правило мастер-теоремы и ответом является:
, то срабатывает второе правило мастер-теоремы и ответом является:
![\[ T(n) = \Theta(n^{\log_2 1} log_2 n) = \Theta(\log_2 n) \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-622636399d4d10e1d99878b625329472_l3.svg "Rendered by QuickLaTeX.com")
Рассмотрим другой пример рассмотренный раннее. Пусть:
![\[ T(n) = 4T(\frac{n}{2}) + kn \]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-984db3c8274e75cd1b54e5693185de6d_l3.svg "Rendered by QuickLaTeX.com")
Попробуем применить 3-е правило мастер теоремы, где a = 4, b = 2 и проверить утверждение, что:  Но, поскольку функция kn не может быть оценена снизу, т.е.
Но, поскольку функция kn не может быть оценена снизу, т.е.  для любого ϵ > 0, то это правило не может быть применено.
для любого ϵ > 0, то это правило не может быть применено.
Попробуем применить 2-ё правило мастер теоремы, тогда:  , но и в этом случае оно не работает, т.к.
, но и в этом случае оно не работает, т.к.  .
.
Рассмотрим первое правило  . В этом случае
. В этом случае  при 0 < ϵ ≤ 1. Тогда
при 0 < ϵ ≤ 1. Тогда  .
.